
想要正确写好网站的robots文件,首先则必须robots文件的进行基本的了解:
例如:robots文件中User-agent后面加上*号,则表示允许所有搜索引擎抓取收录网站,如果User-agent后面加的是Baiduspider,则表示的是只允许百度搜索引擎抓取网站,其它的搜索引擎蜘蛛不允许抓取。

Robot.txt文件
一、robots.txt文件基础知识讲解
Disallow:这个函数后面加某个目录url地址则表示的意思是禁止搜索引擎抓取收录的页面,如果禁止全站抓取索引,则Disallow:后面不加任何东西,
Allow:这个函数后面加的数值表示的意思是允许搜索引擎访问索引的URL地址,这个数值可以是一条完整的URL路径地址,也可以是某些url目录地址的前缀,例如“Allow:/zhishi”,表示的是允许搜索引擎访问/zhish.html、/seozhishi.html,也可以是/zhish/123.html,网站其它的url地址既没有加Allow也没有加Disallow,那么这些url地址就是默认允许被访问的,所以Allow和Disallow一般都是搭配使用的,如果要实现允许搜索引擎访问一部分网页同时又要禁止访问其它所有URL的功能,那么我们可以使用通配符”*”and”$”:Baiduspider,”*”和”$”是用来来模糊匹配url地址的。
“*” 可以匹配0或多个任意字符;
“$” 则表示匹配行结束符。
第二:设置Robots.txt文件时应注意哪些事项?
robots文件往往放置于根目录下,包含一条或更多的记录,这些记录通过空行分开(以CR,CR/NL, or NL作为结束符),每一条记录的格式如下所示:
“<field>:<optional space><value><optionalspace>”
在该文件中可以使用#进行注解,具体使用方法和UNIX中的惯例一样。该文件中的记录通常以一行或多行User-agent开始,后面加上若干Disallow和Allow行,详细情况如下:
User-agent:该项的值用于描述搜索引擎robot的名字。在”robots.txt”文件中,如果有多条User-agent记录说明有多个robot会受到”robots.txt”的限制,对该文件来说,至少要有一条User-agent记录。如果该项的值设为*,则对任何robot均有效,在”robots.txt”文件中,”User-agent:*”这样的记录只能有一条。如果在”robots.txt”文件中,加入”User-agent:SomeBot”和若干Disallow、Allow行,那么名为”SomeBot”只受到”User-agent:SomeBot”后面的 Disallow和Allow行的限制。
Disallow:该项的值用于描述不希望被访问的一组URL,这个值可以是一条完整的路径,也可以是路径的非空前缀,以Disallow项的值开头的URL不会被 robot访问。例如”Disallow:/help”禁止robot访问/help.html、/helpabc.html、/help/index.html,而”Disallow:/help/”则允许robot访问/help.html、/helpabc.html,不能访问/help/index.html。”Disallow:”说明允许robot访问该网站的所有url,在”/robots.txt”文件中,至少要有一条Disallow记录。如果”/robots.txt”不存在或者为空文件,则对于所有的搜索引擎robot,该网站都是开放的。
Allow:该项的值用于描述希望被访问的一组URL,与Disallow项相似,这个值可以是一条完整的路径,也可以是路径的前缀,以Allow项的值开头的URL 是允许robot访问的。例如”Allow:/hibaidu”允许robot访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。一个网站的所有URL默认是Allow的,所以Allow通常与Disallow搭配使用,实现允许访问一部分网页同时禁止访问其它所有URL的功能。
使用”*”and”$”:Baiduspider支持使用通配符”*”和”$”来模糊匹配url。
“*” 匹配0或多个任意字符
“$” 匹配行结束符。
最后需要说明的是:百度会严格遵守robots的相关协议,请注意区分您不想被抓取或收录的目录的大小写,百度会对robots中所写的文件和您不想被抓取和收录的目录做精确匹配,否则robots协议无法生效。
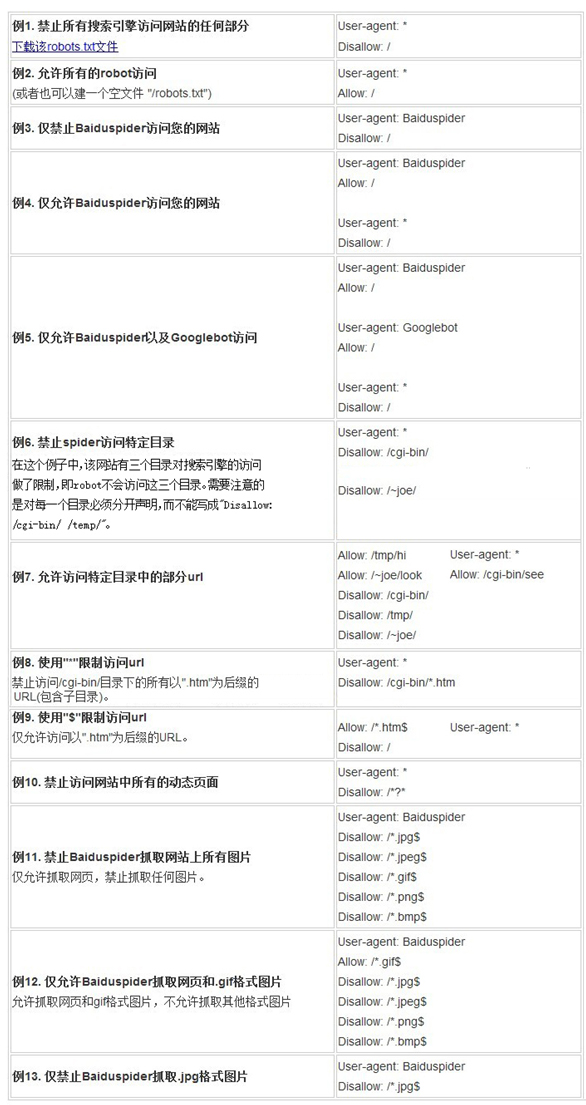
robots.txt文件用法举例:
网站误封Robots该如何处理
robots文件是搜索生态中很重要的一个环节,同时也是一个很细节的环节。很多站长同学在网站运营过程中,很容易忽视robots文件的存在,进行错误覆盖或者全部封禁robots,造成不必要损失!
网站Robots文件误封处理方式:
1、修改Robots封禁为允许,然后到百度搜索资源后台检测并更新Robots。
2、在百度搜索资源后台抓取检测,此时显示抓取失败,没关系,多点击抓取几次,触发蜘蛛抓取站点。
3、在百度搜索资源后台抓取频次,申请抓取频次上调。
4、百度反馈中心,反馈是因为误操作导致了这种情况的发生。
5、百度搜索资源后台链接提交处,设置数据API推送(实时)。
6、更新sitemap网站地图,重新提交百度,每天手动提交一次。
以上处理完,接下来就是等待了,一段时间后网站索引数据会开始慢慢回升,直至网站索引数据恢复到正常状态!
北京爱品特SEO网站优化提供专业的网站SEO诊断服务、SEO顾问服务、SEO外包服务,咨询电话或微信:13811777897 袁先生 可免费获取SEO网站诊断报告。
北京网站优化公司 >> SEO资讯 >> SEO技术技巧 >> Robots.txt文件要如何正确设置 本站部分内容来源于互联网,如有版权纠纷或者违规问题,请联系我们删除,谢谢!
下一篇:网站robots文件常见问题总结

售后响应及时
全国7×24小时客服热线
数据备份
更安全、更高效、更稳定
价格公道精准
项目经理精准报价不弄虚作假
合作无风险
重合同讲信誉,无效全额退款





 SEO技术技巧
SEO技术技巧 SEO算法解析
SEO算法解析 公司动态
公司动态 公司简介
公司简介 我们的观点
我们的观点 为什么选择我们
为什么选择我们 企业文化
企业文化 联系方式
联系方式 在线留言
在线留言 提交意向表
提交意向表 在线客服
在线客服 来访路线
来访路线







