
robots是搜索引擎爬虫协议,也就是你网站和爬虫的协议。
简单的理解:robots是告诉搜索引擎,你可以爬取收录我的什么页面,你不可以爬取和收录我的那些页面。robots很好的控制网站那些页面可以被爬取,那些页面不可以被爬取。
主流的搜索引擎都会遵守robots协议。并且robots协议是爬虫爬取网站第一个需要爬取的文件。爬虫爬取robots文件后,会读取上面的协议,并准守协议爬取网站,收录网站。
robots文件是一个纯文本文件,也就是常见的.txt文件。在这个文件中网站管理者可以声明该网站中不想被robots访问的部分,或者指定搜索引擎只收录指定的内容。因此,robots的优化会直接影响到搜索引擎对网站的收录情况。
robots文件如下图

存放目录
robots文件必须要存放在网站的根目录下。也就是 域名/robots.txt 是可以访问文件的。你们也可以尝试访问别人网站的robots文件。 输入域名/robots.txt 即可访问。
如下图
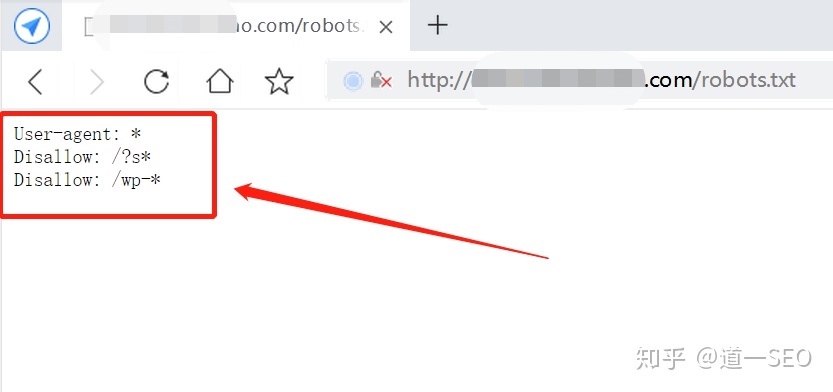
robots写作语法
首先我们来看一个范例(下图)
user-agent这句代码表示那个搜索引擎准守协议。user-agent后面为搜索机器人名称,如果是“*”号,则泛指所有的搜索引擎机器人;案例中显示“User-agent: *” 表示所有搜索引擎准守,*号表示所有。
Disallow是禁止爬取的意思。Disallow后面是不允许访问文件目录(你可以理解为路径中包含改字符、都不会爬取)。案例中显示“Disallow: /?s*” 表示路径中带有“/?s”的路径都不能爬取。 *代表匹配所有。 这里需要主机。 Disallow空格一个,/必须为开头。
如果“Disallow: /” 因为所有路径都包含/ ,所以这表示禁止爬取网站所有内容。
如果没有被禁止到的路径,默认为可以被爬取。
关于robots的注意事项
1、不要禁止爬虫爬取网站的所有,因为从经验来看,如果屏蔽一次,解封后好一段时间爬虫都不会来你网站,收录成为问题。
2、代码后需要【冒号+空格+斜杆】 ,比如“Disallow: /*?* ”
3、当网站为静态路径时,需要屏蔽掉所有动态链接。网站中存在一种链接被收录即可,避免一个页面2个链接。代码如下“Disallow: /*?* ”表示禁止所有带 ?号的网址被爬取。通常动态网址带有“?”“=”等。
4、根据自己网站情况定,屏蔽不需要收录的网址。
北京爱品特SEO网站优化提供专业的网站SEO诊断服务、SEO顾问服务、SEO外包服务,咨询电话或微信:13811777897 袁先生 可免费获取SEO网站诊断报告。
北京网站优化公司 >> SEO资讯 >> SEO技术技巧 >> 关于网站robots协议,看这篇就够了 本站部分内容来源于互联网,如有版权纠纷或者违规问题,请联系我们删除,谢谢!

售后响应及时
全国7×24小时客服热线
数据备份
更安全、更高效、更稳定
价格公道精准
项目经理精准报价不弄虚作假
合作无风险
重合同讲信誉,无效全额退款





 SEO技术技巧
SEO技术技巧 SEO算法解析
SEO算法解析 公司动态
公司动态 公司简介
公司简介 我们的观点
我们的观点 为什么选择我们
为什么选择我们 企业文化
企业文化 联系方式
联系方式 在线留言
在线留言 提交意向表
提交意向表 在线客服
在线客服 来访路线
来访路线







